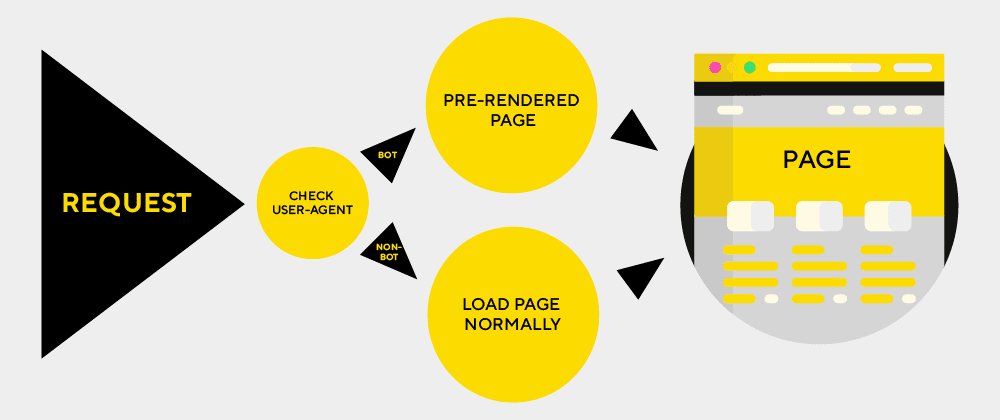
Ever got in a fight with social network crawlers or any other kind of bots? Yeah, join the club. So, what happened out there? It seems that you coded your web SPA perfectly fine and it works great on any resolution possible. However, social media bots just can’t render it right which means that nobody can share links of your web app anywhere on the internet to get a nice preview.
The problem
Most web crawlers CAN’T execute JavaScript. Well, why I am concerned with that? Quick recap: SPA works in a way that it redirects all network requests to a single file (eg. index.html) and after that, an internal router takes over and handles the request like it should (eg. takes the user to a blog detail page) but that part is done via JavaScript library (eg. vue-router). So if you, for example, share on Twitter link “https://mysite.com/blogs/cool-blog-slug” twitter bot will try to fetch the contents of a page on that link but it will only receive “naked” HTML content from “index.html” file. Why? Because it can’t execute JavaScript and internal SPA router didn’t run the logic around serving the proper sub-page.
The solution
Many ideas were taken into account and tried before we decided to take this particular approach to solving this problem. In essence, the key part is to figure out when a bot/crawler is initiating a request to our site and intercept it. Once we do that, we must somehow serve the “clean” HTML with already executed JavaScript code. But how?
In this article we’ll take an example of an SPA done in Nuxt.js framework which is a wrapper around Vue.js framework. SPA is running on the Ubuntu server instance under Apache server software with installed PHP.
Intercepting bot request
We’ll intercept incoming requests as soon as possible and the entry point of our web app is in the root of our public SPA folder. Having Apache software installed means that you should have an .htaccess file that looks something like this:
RewriteEngine on
# for all routes serve index.html
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^ /index.html [L]It means “serve all requests from a single file – index.html” as we explained earlier. Let’s mingle with it a little and add a few lines to detect if the request is a “bot one”:
RewriteEngine on
# bot redirect
RewriteCond %{HTTP_USER_AGENT} facebookexternalhit|twitterbot|linkedinbot [NC]
RewriteCond %{REQUEST_URI} ^(?!.*?(\.js|\.css|\.xml|\.less|\.png|\.jpg|\.jpeg|\.gif|\.pdf|\.doc|\.txt|\.ico|\.rss|\.zip|\.mp3|\.rar|\.exe|\.wmv|\.doc|\.avi|\.ppt|\.mpg|\.mpeg|\.tif|\.wav|\.mov|\.psd|\.ai|\.xls|\.mp4|\.m4a|\.swf|\.dat|\.dmg|\.iso|\.flv|\.m4v|\.torrent|\.ttf|\.woff|\.svg))
RewriteRule ^ bots.php?url=%{REQUEST_SCHEME}://%{HTTP_HOST}%{REQUEST_URI} [QSA,L]
# for all routes serve index.html
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^ /index.html [L]This extra three lines will look for a specific case-insensitive strings in the User-Agent request header field and, if found a match, redirect the request to a specific bots.php file. Notice how we only redirect requests that need to be specially served as clean HTML (eg. there’s no need to redirect a request for an image or any kind of static asset).
Resolve HTML in custom handler
For now, our public folder has three files: .htaccess, index.html and bots.php. As seen earlier, all our bot requests will end up in bots.php file with url param being populated with incoming request URL.
Being a company that has PHP in its regular stack, we decided to go with a solution that uses PHP for that – spatie/browsershot. Under the hood package uses Puppeteer for rendering HTML which is in essence a Headless Google Chrome.
Package has extensive documentation on how to set it up, but you should first use Composer package manager to install it in the root of your project (not in public folder!).
Let’s now take a look at bots.php file:
<?php
ob_start();
// composer autoloader
require_once __DIR__ . '/../vendor/autoload.php';
use Spatie\Browsershot\Browsershot;
// url param from redirection
$output = browsershot($_GET['url'] ?? null);
// clean all output and echo just browsershot output
ob_clean();
echo $output;
ob_end_flush();
function browsershot(?string $url = null)
{
// fallback to "root" url
$url = $url ?? $_SERVER['REQUEST_SCHEME'] . '://' . $_SERVER['HTTP_HOST'];
return Browsershot::url($url)
->noSandbox()
->dismissDialogs()
->waitUntilNetworkIdle()
->bodyHtml();
}And that’s it! You have a working prerendering for bots!
Some caveats that you’ll probably figure out by yourself:
Browsershot needs node to internally call puppeteer. We had a situation where Node.js was installed using NVM in a user home folder – in particular on AWS hosting it’s ubuntu user. When PHP script is executing it probably won’t find node binaries because it’s executing as a root user. So what do you do?
You have a few options here but we took an approach where you instruct Browsershot to look for node binaries in some custom folder and not predefined one:
function browsershot(?string $url = null)
{
// fallback to "root" url
$url = $url ?? $_SERVER['REQUEST_SCHEME'] . '://' . $_SERVER['HTTP_HOST'];
return Browsershot::url($url)
->setIncludePath('$PATH:' . getNodeDir()) // custom node path
->noSandbox()
->dismissDialogs()
->waitUntilNetworkIdle()
->bodyHtml();
}
function getNodeDir()
{
$nodePath = trim(shell_exec('which node'));
// when node is installed in "root" mode
if (!empty($nodePath)) {
return dirname($nodePath);
}
// take latest version installed from home folder
$nodeVer = scandir('/home/ubuntu/.nvm/versions/node', SCANDIR_SORT_DESCENDING)[0] ?? null;
return empty($nodeVer) ? null : '/home/ubuntu/.nvm/versions/node/' . $nodeVer . '/bin';
}
The same goes for puppeteer binaries. It depends if you’ve installed it globally or locally. I would suggest globally if you can because it drags Headless Chrome with it (over 130 MB) so that every project can use it.
If that’s not the case (local instalation), you can tweak Browsershot to look for local node_modules folder by specifying a custom path for it:
->setNodeModulePath(__DIR__ . '/../node_modules')
My advice is to read complete Browsershot documentation to tweak it to your needs.
Other solutions
1) Rendertron – Local Headless Chrome server on specific port
2) Prerender.io – paid service that you can use (the easiest setup approach)